
There are two ways of extracting information from a line of log data. You can use a regular expression pattern on normal data or use the split function when you come across more structured text data like csv files. The split function and regex pattern can be used on the search or data types page. Each group that is extracted is numbered and can be assigned to a field name when used on the Data types page or be used as a search term as part of a search expression. The Regex library in use in Logscape is JRegex, which is a Perl5 compliant Regex implementation.
Here are a few example searches of patterns being used on the search page
Example 1 - Search with a regex patternEach group defined in the regex pattern is labelled with a number.
cpu=(\d+)% | 1.max() chart(line)
The number representing the group can then be used as a search term. In this example the cpu percentage is extracted and plotted as a line chart.
2014-03-11 11:23:00 HPCSVR0001 Server Health Metrics cpu=34% mem=26% diskUtilization=0.1% 2014-03-11 11:23:10 HPCSVR0001 Adding Node 0001 to cluster BigDataNode 2014-03-11 11:23:12 HPCSVR0001 Adding Node 0002 to cluster BigDataNode 2014-03-11 11:23:17 HPCSVR0001 Adding Node 0003 to cluster BigDataNodeExample 2 - Search with the split function
The split function is handy when working with delimited or CSV data. Often it is the simpler option when it comes to more structured text.
split(\|,7) | 7.avg(3,cpuMS) chart(stacked)
Each column is mapped or labelled with a number and can be used as a search term. Column 7 represents the cpu time of a task and column 3 is the node Id. The resulting chart plots the average cpu time of each nodeId.
#datetime|server|nodeId|taskname|startTime|endTime|avgCpuTImeMs 2014-03-11 11:23:00|HPCSVR0001|00abc0343da|riskcalc001|2014-03-11 11:20:00||300 2014-03-11 11:23:10|HPCSVR0001|007dfa333a2|riskcacl002|2014-03-11 11:20:00||370 2014-03-11 11:23:12|HPCSVR0001|001aaabe453|IRriskCalc002|2014-03-11 11:20:00||450 2014-03-11 11:23:17|HPCSVR0001|0022abefeaa|IRriskCal002|2014-03-11 11:20:00||600
Any data extracted from a log line can be assigned to a field name in a datatype. A type at its simplest is a collection of named field extractions. A regex pattern or the split function can be used on this page. Here are few data type mappings using a pattern or a split expression.
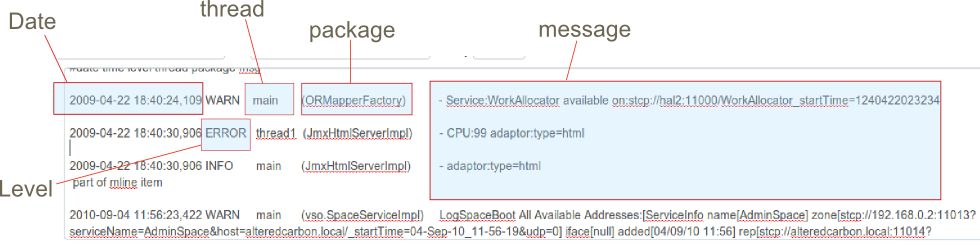
Example 1 - Datatype for a log4j style logEach matched group is mapped sequentially to the field names defined in the data type. The example uses the perl regex syntax. The ^ symbol is optional.
Pattern: ^(2*)\s+(INFO|DEBUG|WARN|ERROR|FATAL)\s+(*)\s+(*)\s+(**)
Each
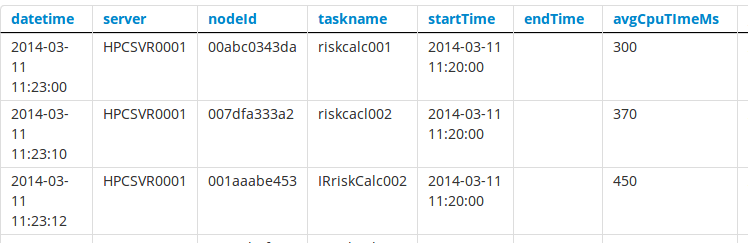
The split function works on csv data. This example splits the text 7 times with the delimiter '|' and then maps the values sequentially to a field name
split(\|,7)
The first column is mapped to the datetime field, the second to the server name, the third to the nodeId field and so on.
Logscape provides a few regex shortcuts to make them easier to read when used on the search or data type page. Here is a summary of the shortcuts and what they translate to.
