
Examples:
Exception | not(Runtime)
type='log4j' | contains(WARN,ERROR,FATAL)
Examples:
type='log4j' | contains(Exception)
type='log4j' | level.contains(WARN,ERROR,FATAL)
Examples:
type='agent-stats' | cpu.gt(60) cpu.avg(_host,) chart(line)
type='agent-stats' | cpu.gt(20) cpu.lt(60) cpu.avg(_host) chart(line-zero)
Examples:
| hosts(acme,dc)
type='agent-stats' | hosts(cache,db) cpu.avg(_host) chart(line)
Examples:
type='agent-stats' | cpu.avg(_host) top(5) chart(pie) buckets(1)
type='www-xlf' | userAgents.count(_host,) top(7)
Examples:
type='agent-stats' | cpu.avg(_host) bottom(5) chart(pie) buckets(1)
type='www-xlf' | userAgents.count(_host,) bottom(5)
Examples:
type='java-heap' | used.avg(_host,) chart(area)
type='agent-stats' | cpu.avg() _host.equals(cache.dc0.acme)
Examples:
(*)Exception | 1.count() _filename.equals(app.log)
* | _host.count() _tag.equals(coherence-logs)
Examples:
| _type.equals(weblogs) refererHost.countUnique() chart(table) buckets(1)
Examples:
| _type.equals(log4j) cpu.last(_host,) buckets(1) chart(table)
Examples:
WARN (*) | 1.countSingle()
* | chart(stacked) _host.countSingle()
Examples:
(*)Exception | 1.countDelta()
type='coh-logs' member:(*) | 1.countDelta()
Examples:
type='agent-stats' | mem.max() _host.count()
type='agent-stats' | mem.max(_host,)
Examples:
type='db-caches' | storageUtilized.sum(cacheNodeId,)
type='unx-df' | diskMB.sum()
Examples:
| cpu.avg(line-connect)
type='unx-io' | diskUtil.max(_host,) chart(area)
Examples:
type='unx-mem' | memutil.avg(_host,) chart(pie) buckets(1)
| mem.avg(_host,) chart(clustered) buckets(5)
Examples:
| bucketWidth(1m) _host.count() type.equals(log4j)
| membersJoined.count(nodeId,) bucketWidth(30s)
Examples:
#EXAMPLE1
#EXAMPLE2
Examples:
type='log4j' ERROR OR WARN | replay(false) _host.count()
(*)Exception | 1.count() chart(stacked) replay(false)
Examples:
| _type.contains(unx-io,unx-bw,unx-cpu,unx-df,unx-free,unx-pcount) pcount.last(server,pcount%-) await.max(server,diskWaitMs-) rxMBs.max(server,rMBs-) txMBs.max(server,sMBs-) CpuUtilPct.avg(server,cpu%-) FsUsedPct.max(server,diskUsedPct) memUsedPct.avg(server,memUsedPct) chart(table) buckets(1) sort(2, asc)
Examples:
| _type.contains(unx-io,unx-bw,unx-cpu,unx-df,unx-free,unx-pcount) pcount.last(server,pcount%-) await.max(server,diskWaitMs-) rxMBs.max(server,rMBs-) txMBs.max(server,sMBs-) CpuUtilPct.avg(server,cpu%-) FsUsedPct.max(server,diskUsedPct) memUsedPct.avg(server,memUsedPct) chart(table) buckets(1) sort(2, asc)
Examples:
| _host.count () ttl(10)
Examples:
Performance | msg.elapsed(Total,Start Batch, End Batch,m) chart(clustered)
Task | msg.elapsed(timeTaken,task start,task end)
Examples:
* | USED.values()
Examples:
* | USED.avgDelta()
Examples:
* | USED.avgDeltaPc()
Examples:
* | _type.equals(win-cpu) ProcessorPct.percentile(,) chart(line)
* | _type.equals(win-cpu) ProcessorPct.percentile(,96) chart(line)
Examples:
transform(groovy-script: [my-groovy-script])
Examples:
Eval a host grouped by another value
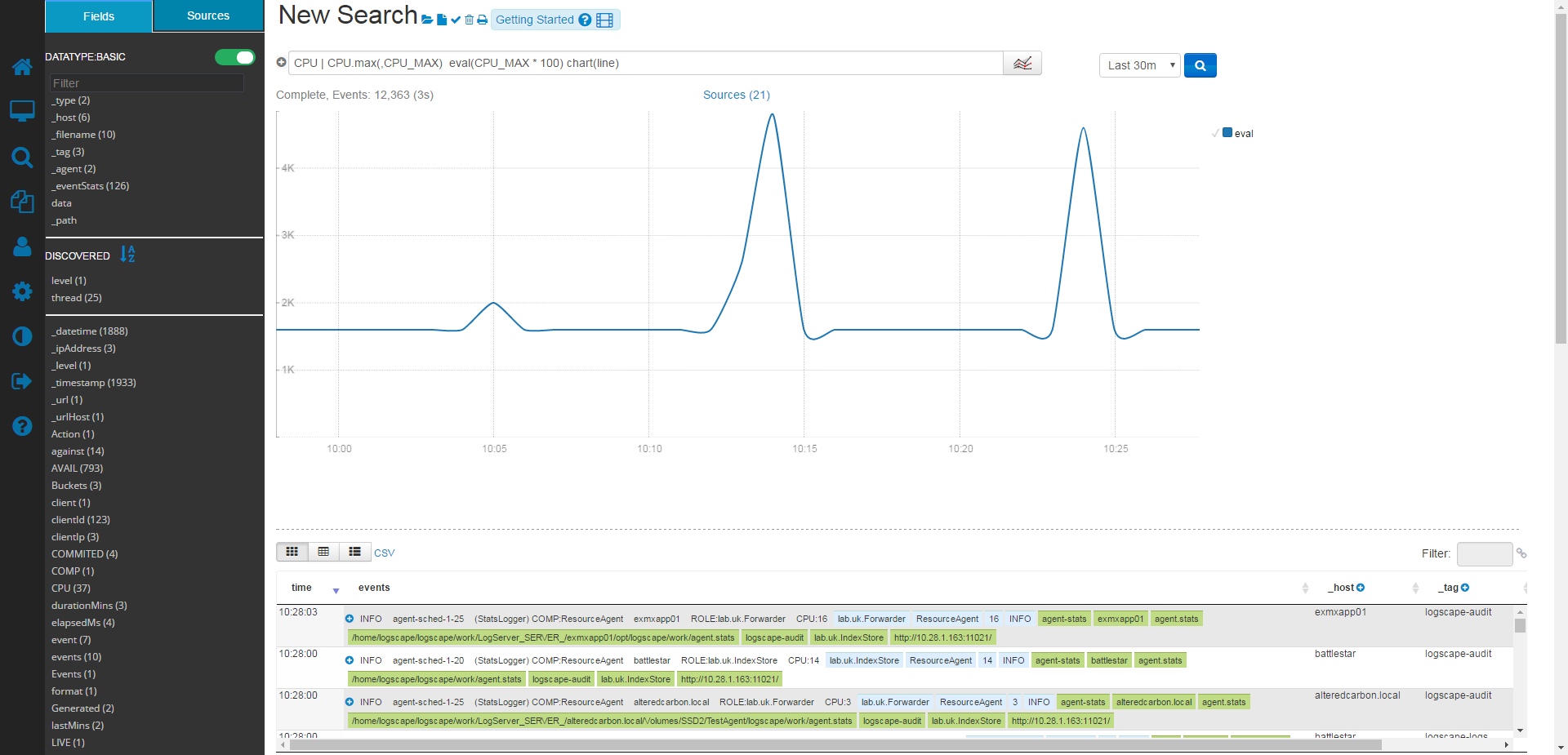
CPU | CPU.max(_host,M) eval(EACH * 100)
This will multiply the Max CPU for each host, resulting in

You can also use eval on alias fieleds, such as
CPU | CPU.max(,CPU_MAX) eval(CPU_MAX * 100)
Examples:
* | _type.equals(Unx-CPU) Cpu.trend(,AverageAcross) buckets(5m)
Due to the 5 minute bucket size, trend would provide averages from past 50 and past 100 minutes.